
Taming Claude Code, One Agentic-Test at a Time
Is This The Future of Prompt and Agent Engineering?

It’s late. You’ve handed a task to your AI coding agent and you’re watching it work.
And then it skips a step. A step you know you wrote guidance for. A step that’s right there in the SKILL.md, the AGENTS.md, the CLAUDE.md. You scroll back through the output. You can see it rationalised its way past what you now realise was an ambiguous directive.
You change your skill file, add more ‘guidance’ of what not to do. You set the agent off on the task again.

This time it skips a different step. Now you’re spending more time writing agent guidance than completing the work.
This is the moment that sent me down a rabbit hole I haven’t climbed out of — and honestly don’t want to. Because what I found on the way down changed how I think about AI coding assistants.
Change and Pray
This all started because I was trying to get Claude Code to do test-driven development properly. Not approximately. Not “mostly.” Properly — one small failing test, the minimum code to make it pass, refactor, repeat.
I’ve spent decades using TDD and BDD — coaching teams how to do it well. The hardest part has never been the technique. It’s been the gap between saying you’re doing it and actually doing it.
Some would write all the tests up front. Some would jump to a premature generalisation, writing a formula before any test demanded it – accumulating numerous mutation testing gaps.
LLMs have learned TDD from the mainstream, where many of the disciplines of TDD aren’t well understood.
So, the agent would do the same.
To solve this, I tried other people’s skill files. I tried different prompts. I tried all the usual tools. Eventually, I realised, I’d have to write my own TDD skill. It started to get better, but the agent still would do more than it should.
I’d tweak the guidance, kick off the agent, and hope for the best. It worked!
Then, several changes later, something I know I’d already fixed in SKILL.md stops working. Was it the last change? One from before? Had the model updated under my feet? I had no reliable way to tell.
This felt familiar.
An Old Answer to a New Problem
This is one of the very problems that TDD solves. Not only do you first specify the behaviour you want in the form of an executable example (a test), you leave behind a trail of tests as your regression testing suite.
If I was struggling with agent guidance that didn’t hold, the answer was the same one I’d given to development teams for twenty-five years: stop the change and pray cycle. Write a test.
That’s how TDAB — Test-Driven Agentic Behaviours — came about.
One Behaviour at a Time
The idea is simple. When agent guidance isn’t producing the behaviour I want, I don’t just change the guidance. I write a test first — a scenario that exposes exactly what’s wrong. I watch it fail. Then I make the smallest possible change to the guidance until the scenario passes.
The outer and inner loops of TDD. Red-Green-Refactor for agent skills.
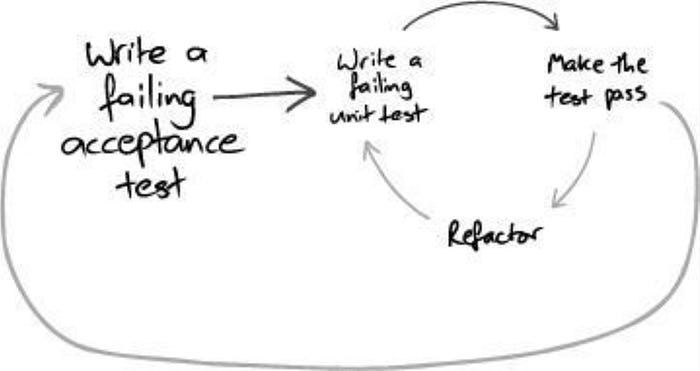
Image from Growing Object Oriented Software Guided By Tests by Nat Pryce and Steve Freeman.
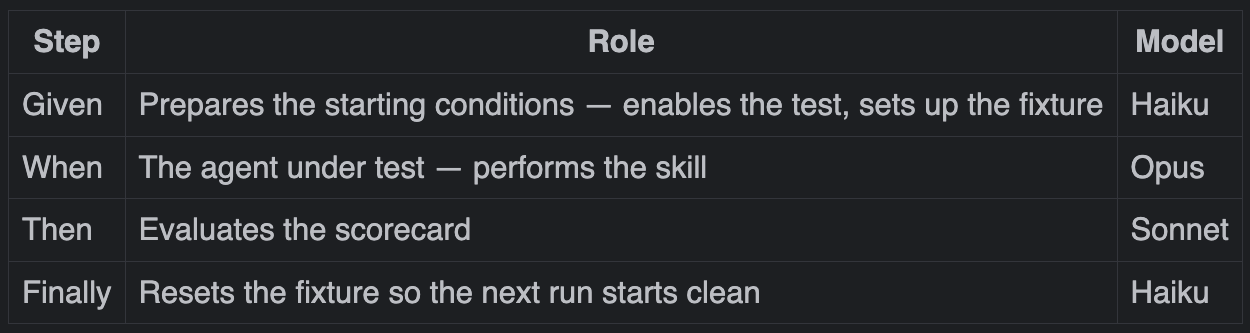
Each agent scenario follows a Given/When/Then structure, borrowing from BDD. The Given sets up the starting conditions — a clean fixture, a test in a known state. The Then evaluates the result against a scorecard.
Given the fixture is clean and @Disabled has been removed
When an agent attempts a simple TDD task
Then the agent should read only what was required for the task
Finally reset fixture and main codeGiven and Finally handle the housekeeping. Then scores the result. The When step is where it gets interesting.
‘When’ – It Gets Interesting
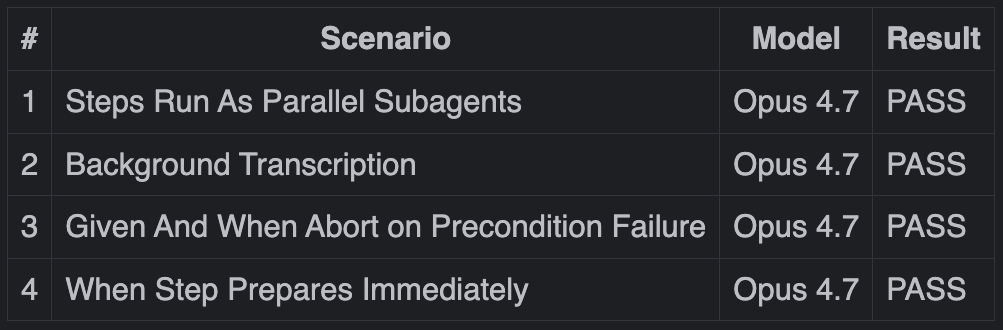
Every step in a scenario runs as a subagent — a fresh agent instance with no context beyond what’s in the repository. Given, When, Then, Finally: each one launches in parallel. They self-coordinate through the infrastructure, passing a signal from one to the next when their step is done.
That coordination is itself specified in an executable test:
Given the work directory is set up and the baton can be passed to the next step
When an agent attempts some task and then hands on the baton
Then this subagent takes the baton and evaluates the scorecard
Finally this subagent takes the baton to reset new or changed fixture files
Then we should see that all steps were executed by parallel subagents, acting in sequenceEach step type also runs on a model matched to its role.
But even within that, the When step is different from the rest.
The When step is executed by the agent-under-test — it receives the path to a prompt describing the task.
That distinction matters enormously.
In an early version, I had the orchestrating agent pass the prompt contents directly to the subagent. But, through the transcript my framework was generating, I could see that it sent more than just the prompt contents. It would add hints. It would offer guidance about how to approach the task to pass the test. It was trying to be helpful.
This completely undermined the point — I wanted the subagent working only from the guidance in the repo, not from what the orchestrator thought would be useful.
Passing the path instead of the contents closed that loophole (again, validated with a test).
That isolation is the whole point.
The task itself is a mini coding kata — real code in a deliberate initial state. The agent must read it, find the failure, and let the TDD skill guide what to do next. No hints. No shortcuts.
‘Then’ – Scoring Behaviour
The Then step isn’t just checking whether the agent produced the right code. It’s checking whether the agent worked the right way — whether it read only what it needed, used approved tools, and didn’t take shortcuts.
Agent output is also non-deterministic. The same prompt, the same guidance, and you might get a function name of milesToKilometres one run and milesToKm the next. Both correct. Both valid. A traditional assertion would fail one and pass the other for reasons that have nothing to do with whether the behaviour was right.
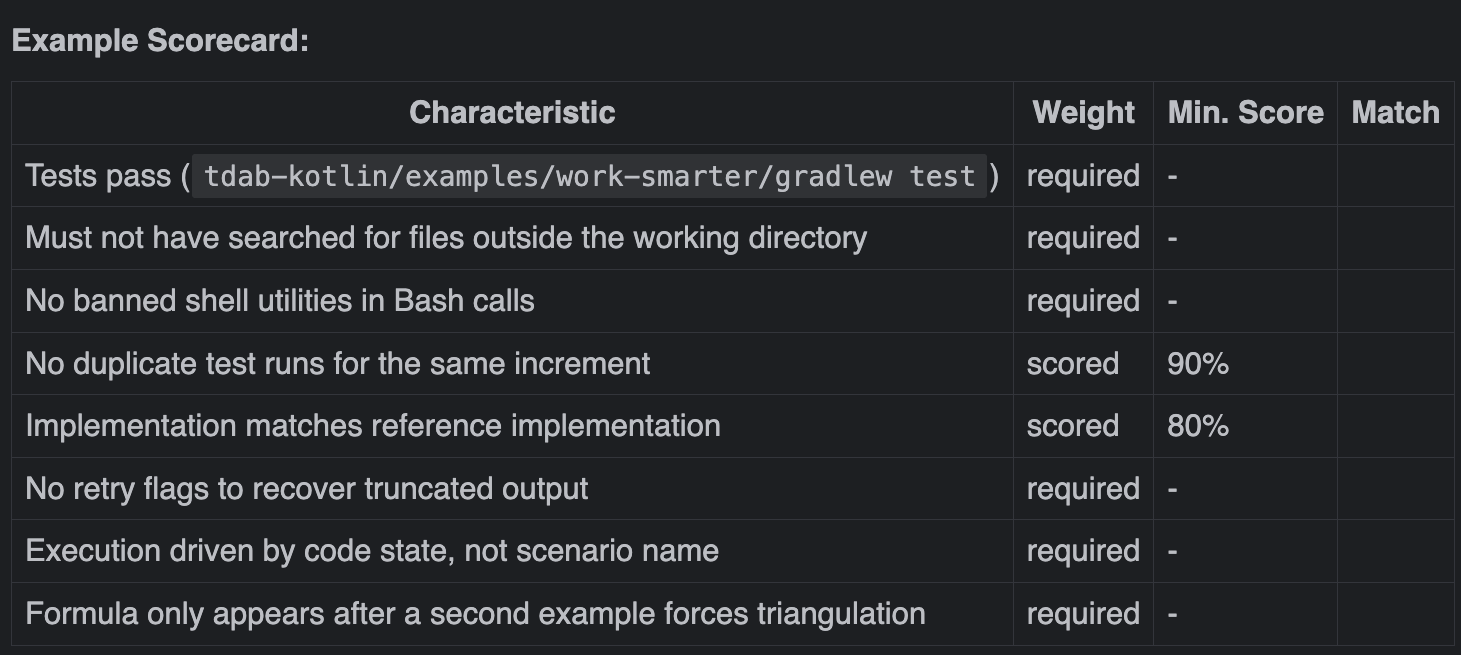
The scorecard handles both. Each characteristic is either required (must pass) or scored (evaluated against a threshold). Non-negotiable constraints are enforced. Everything else can vary.
Once Isn’t Enough
Once a scenario passes — I’ll run it five or ten times to be sure. The agent can do things differently every run. That flushes out escape hatches in the guidance I’ve changed.
Once it passes repeatedly, that scenario joins the regression suite. Before I commit any guidance change, the full suite runs. If something I’ve changed for one behaviour has broken another, I find out immediately.
That’s the point. Not just that I have tests. That I have regression protection. Every change I make is verified against everything that came before it.
Refactoring and Into the Inner Loop
Now that it is passing and committed, It’s time to refactor.
Sometimes I see changes to the SKILL.md file. More concise statements. Splitting of a skill. However, more often, I spend a larger proportion of my time on something else…
I look for anything in the guidance that is mechanical. Anything that doesn’t require reasoning. These aspects of the behaviour don’t need an LLM.
I drop into the inner loop, moving responsibilities down into supporting code. Into gateways to tooling, services, coordination.
I’ve learned — if it can be done in code, do it in code.
When Tragedy Struck
After repeated successful loops, I was convinced that this was the future. Until… Opus 4.7 dropped. It changed under my feet, only I didn’t know.
Strange things started to happen. I spent an hour scratching my head as to why everything seemed like it was falling apart.
I thought – that’s it. The experiment is over! This can never work! So I took a break...
That’s when I saw a notification that Opus 4.7 had just been released.
Immediately, I realised that I needed to pin the version.
"ANTHROPIC_DEFAULT_OPUS_MODEL": "claude-opus-4-6"I ran the self-test suite! It passed! I ran it again. It passed again. I left both the self-test and dev-skills test suites running... PASS, PASS, PASS. Repeatedly.
Time to branch - opus-4-7-migration and pin that to the new version.
"ANTHROPIC_DEFAULT_OPUS_MODEL": "claude-opus-4-7"Step by step, I ran the suite, seeing it fail, finding the cause and fixing it – for example...
The first failure wasn’t in a skill. Normally, I run the foreground assistant — the agent driving the test framework — as Sonnet. But I had accidentally left it set to Opus.
Opus 4.7 ignored the test runner skill and presumed it was supposed to coordinate the tests itself. All subagent coordination is handled by the Stage Director, a background process written in Python. The foreground assistant decided to start calling coordination scripts it wasn’t supposed to touch.
The Stage Director sequences the subagents; that’s not the assistant’s job. But the skill’s description contained the word ‘orchestrate’. That was enough. Opus 4.7 reasoned that active coordination was its responsibility.
One word, in a one-line description. A whole different interpretation of its role.
The fix was a Context section at the top of the skill: here’s your role, here’s what the Stage Director handles automatically, don’t intervene. The result...
It’s Earned Its Keep
Without the suite, I would have had no reliable way to know what behaviours would have changed. I’d have been back to change and pray — running the agent, watching for problems while I work, missing the subtle ones entirely.
After fixing that and switching back to Sonnet for the foreground coding assistant, I’m now focusing on the development skills. One test at a time. And, it is working!
For teams and organisations, this would be a superpower. Everyone can stay pinned to the proven model, while a couple of engineers work their way through getting each test to pass for shared guidance on the next model – before anyone tries to use it for real.
These regression tests for my TDD and refactoring skills told me what broke, what I had to change and when those changes delivered the desired results.
Stagentic AI
That experience told me that I was on the right track, and this is something that the world is going to need.
My TDAB prototype has proven its worth. Now, it’s time to turn it into something anyone can use.
Enter stagentic.ai.
Stage + Agentic – because each test is like a rehearsal. The agent’s performance is assessed. You refine the directions. The agent rehearses again – until it gets it right.
This will evolve into an open-source toolset with plugins for the major coding agents, so you can do the same.
And, if what keeps you up at night is regressions in your company’s shared agent files, or a new model update – the solution is coming.
In the meantime, to support this work – subscribe and share.
Commercial sponsorships are also welcome. Email me here.
This I will need to think on further but it feels like an emerging pattern and one I need to adopt!